29th Annual RESNA Conference Proceedings
Inarticulate Speech Recognition for the Control of Wheelchairs by the Severely Disabled
Hiroaki Kojima, Shi-Wook Lee, Akira Sasou, Ken Sadohara and Soo-Young Suk
Information Technology Research Institute
National Institute of Industrial Science and Technology (AIST)
Central 2, 1-1-1 Umezono, Tsukuba, Ibaraki 305-856 8, Japan
ABSTRACT
Aiming at enabling severely disabled persons to move independently, we develop wheelchairs which can be operated by inarticulate speech affected by severe cerebral palsy or quadriplegia, for instance. To cope with the pronunciation variation of inarticulate speech, we adopt lexicon building approach based on intermediate speech coding and data mining, in addition to acoustic modeling based speaker adaptation. We also develop noise canceling methods which reduce mechanical noise and environmental sounds for the practical use on the street.
KEYWORDS
Speech recognition, wheelchair control , inarticulate speech , severely disabled
BACKGROUND
This research is concerned with the recognition of inarticulate commands spoken by a disabled person, as a technological aid to support independent movements of the severely disabled. The goal is to develop a speech recognition system that allows users with severe disabilities, such as cerebral pal s y or quadriplegia , to control an electronic wheelchair by voice commands. Currently available conventional systems are designed upon the clear utterances of non-disabled users, resulting in insufficient recognition accuracy for the inarticulate speech of severely disabled users . Therefore, our aim is to develop a speech recognition system that can accommodate such users' voice commands. In addition, methods of reducing noise, such as the whir of the wheelchair and other environmental sounds, are also developed , so as to enable the practical use in a real environment.
INARTICULATE SPEECH RECOGNITION
Factors obstructing recognition of the speech of the severely disabled include 1) the significant difference from the non-disabled by means of the statistical distributions of speech features and duration s ; 2) the frequent insertion of unnecessa ry filler sounds and silent pause; and 3) the subjects' difficulty in stable articulation, which causes pronunciation variations of speech data by each utterance . In evaluating the accuracy of recognition in a real environment , an important emphasis is placed on the need to distinguish commands from other spoken words . Also necessary is an efficient method to adapt speech recognition model s to each user with as few speech samples as possible.
 Photo 1: Directional Noise Reduction (Click image for larger view)
Photo 1: Directional Noise Reduction (Click image for larger view) With regards to 1), we investigate precise acoustic model s based on the HM-Net (Hidden Markov Net) for representing the distribution of inarticulate speech (1) . As a solution to 2) and 3), our research includes the development of a method for detailed modeling of insertions and variation s (2) , by coding speech based on the sub-phon etic segments , which are originally defined by Tanaka (3) . We also investigate a data mining based approach by using Kernel methods based on String Kernel (e.g. the Kernel Principal Component Analysis, the Support Vector Machine) (4) , in order to build a lexicon of reference patterns by extract the code-level characteristics unique to each user, as well as to improve the system's accuracy for distinguishing commands from other s poken words .
NOISE REDUCTION
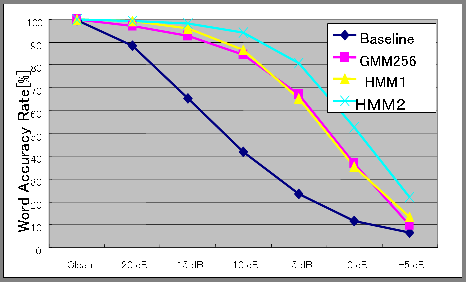 Graph 1: Recognition Rates for AURORA2 Task (Click image for larger view)
Graph 1: Recognition Rates for AURORA2 Task (Click image for larger view) Noise is divided into two categories: a) directional sounds, such as the mechanical noise of the wheelchair, road noise, voices of those standing in proximity, and announcements on the street; and b) non - directional sounds, such as the ambient environmental noise, and mixed noise resulting from complex reflections on walls and other surfaces. For type a) sounds, we apply a noise reduction method based on beam forming by the microphone array with multiple microphones (5) . Our experiments have shown a reduction effect of 12dB in S/N for speech sounds among with TV program sounds issued from two directions by use of an array of eight microphones (Photo 1) . For reducing type b) sounds, we apply a n algorithm based on an original feature compensation method (6) . Evaluated by the AURORA2 experiment, which is a standard assessment task for speech recognition in a noisy environment, our method yielded the recognition rate (word accuracy rate) of 81% for a sound of 5dB in S/N, where the conventional method with the GMM (Gaussian Mixture Model) resulted in the rate of 67% (Graph 1) . Furthermore, the new method improved the recognition rate of pulse noise (5dB in S/N), which cannot be reduced by the GMM, from 77% to 96% (Graph 2) .
COLLECTION OF SPEECH DATA
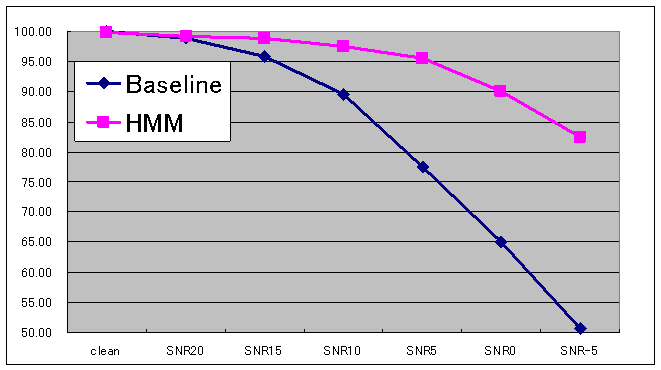 Graph 2 : Recognition Rates for Pulse Noise Task (Click image for larger view)
Graph 2 : Recognition Rates for Pulse Noise Task (Click image for larger view) A large amount of speech samples must be collected in order to train an d elaborat e speech recognition model s , and to evaluate their recognition accuracy. As speech recognition systems are known to show different results for speech sounds in real usage from read speech sounds , it is important for their evaluation to be based on natural spontaneous speech. To this end, we have devised a voice operated toy robot to simulate operation of wheelchair , which enables the efficient collection of spontaneous speech corpus . Th is corpus also include samples taken from non-disabled subjects, allowing analysis into the difference between the speech of the disabled and the non-disabled, as well as into an effective method in filtering out speech coming from non-users such as caretakers . Thus we try not only to develop a brand new speech recognition method but also to accumulat e a wide range of knowledge and detailed analytic data concerning inarticulate speech. Currently, we have collected more than 500 inarticulate speech samples of command words and about 400 samples of other speech sound using four types of microphones including headset, bone-conductive, etc.
FUTURE WORK
 Photo 2: Collection of Speech Data (Click image for larger view)
Photo 2: Collection of Speech Data (Click image for larger view) T he methods discussed above will be further improved and tested out, and implemented as embedded devices mounted on a wheelchair . A method of distinguishing the speech of users from that of others, such as caretakers and third parties, is also an issue for future examination, along with the selection of microphone types robust to noise and vibration , and investigation of their implementation.
REFERENCES
- Suk SY, Lee SW, Kojima H, Makino S, "Multi-mixture based PDT-SSS Algorithm for Extension of HM - Net Structure," Proceedings of the 2005 September Meeting of the Acoustical Society of Japan , 1-P-8 ( 2005 ) .
- Lee SW, Tanaka K, Itoh Y , "Combining M ultiple S ubword R epresentations for O pen- V ocabulary S poken D ocument R etrieval," Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (2005).
- Tanaka K, Hayamizu S, Ohta K, "A Demiphoneme Network Representation of Speech and Automatic Labeling Techniques for Speech Database Construction," Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing: 309-312 (1986).
- Sadohara K, Lee SW, Kojima H, " Topic Segmentation Using Kernel Principal Component Analysis for Sub-Phonetic Segments, " Technical Report of IEICE, AI2004-77: 37-41 (2005).
- Jonson DH, Dudgeon DE , "Array signal processing," Prentice Hall, Englewood Cliffs, NJ ( 1993 ) .
- Sasou A, Asano F, Tanaka K, Nakamura S , "HMM-Based Feature Compensation Method: An Evaluation Using the AURORA2," Proceedings of the International Conference on Spoken Language Processing: 121-124 (2004) .
ACKNOWLEDGMENTS
This research is conducted as part of "D evelopment of technologies for supporting safe and comfortable lifestyles for persons with disabilities, " funded by the s olution o riented r esearch for s cience and t echnology (SORST) p rogram of the Japan Science and Technology Agency (JST), Ministry of Education, Culture, Sports, Science and Technology (MEXT) of the Japanese Government.
Author Contact Information:
Hiroaki Kojima
Information Technology Research Institute
National Institute of Industrial Science and Technology (AIST) Central 2, 1-1-1 Umezono
Tsukuba, Ibaraki 305-8568 , Japan
Office Phone +81-29-862 - 6557
EMAIL: hkojima@ ni.aist.go.jp
This should be in the right column.