Performance of Experienced Speech Recognition Users
Abstract
This paper presents performance measurements for twenty-three individuals who are experienced users of automatic speech recognition (ASR). Users performed a series of word processing and Windows tasks with their ASR system. For eighteen of these users, performance without speech was also measured. The time for non-text tasks was significantly slower with speech (p < 0.05). The average rate for entering text was no different with or without speech. Text entry rate with speech varied widely, ranging from 3 to 32 wpm. Users who had the fastest rates tended to be those who employed the best correction strategies while using ASR.
Background
The focus of this study is on the use of ASR for general-purpose computer access, particularly text entry. Few data are available regarding the performance that users of ASR can expect to achieve. For users without disabilities, reported text entry rates have averaged 25 - 30 words per minute, with recognition accuracy of 94%, after approximately 20 hours of experience [1,2]. Prior to conducting this study, we had found no performance data on ASR users with physical disabilities.
Data from the first nine individuals enrolled in this study have been presented previously [3]. Text entry rate with speech for those nine subjects averaged 13.1 wpm, and recognition accuracy for text averaged 83.5%. Data from an additional 14 users have been collected since then, and this paper reports on the performance of all 23 participants.
Research Questions
The general goals of this three-year project are to understand how well ASR systems are meeting the needs of people with disabilities and to improve user performance with ASR. The specific goals of this study are to measure the performance that experienced ASR users achieve, compare this to non-speech input methods, and identify key factors that influence user-ASR performance.
Method
Design.
Subjects used each of two input conditions to perform a prescribed series of computer tasks: the "Speech-plus" condition involved the use of speech input, and the "No-speech" condition prohibited the use of speech input.
Subjects.
Twenty-three subjects participated. All have physical disabilities that affect their ability to use the standard keyboard and mouse, and all had at least 6 months of ASR experience. Eighteen subjects could perform the tasks with a non-speech alternative. Seventeen of these typed directly on the standard keyboard, and one used an on-screen keyboard. The remaining five subjects entered text only with speech; their data are not included in the comparative analysis between conditions.
Procedure.
Sessions occurred on the subject's own computer. Six word processing and Windows tasks were defined for each input condition. Two were text entry tasks: transcription of a paragraph from hardcopy and a short composition on a supplied topic. The remaining non-text tasks included opening, saving, and moving files; simple text formatting; and browsing and creating folders. The tasks were identical for each condition, except that the transcription text and the composition topic were comparable but not the same. The order of input conditions was counterbalanced across subjects.
Instructions for each task were presented in hardcopy, one task per page. Subjects began each task when they were ready and proceeded at their own pace. In the Speech-plus condition, subjects entered text with speech, but they were also allowed to choose alternative methods, such as direct control of the mouse, to execute commands and make corrections. They were instructed to perform the tasks in the way that they "usually" do.
Data Collection and Analysis.
The subject's computer screen and speech were recorded on videotape to allow for detailed analysis of user actions. Dependent variables were the total time across all six tasks, text entry rate, and recognition accuracy. Correction strategies used to fix recognition errors were also tracked. The text entry rate in words per minute (wpm) includes the time required to correct recognition mistakes. Paired t-tests were performed to compare performance with and without speech.
Results
The overall time required to perform the tasks averaged 31% slower in the Speech-plus condition as compared to No-speech, but this difference was not statistically significant. Considering text entry tasks alone, there was no significant difference between text entry rates with and without ASR. However, use of ASR did provide higher text entry rates for 11 of the 18 subjects. These subjects enjoyed an average enhancement of 92.5% (8.9 wpm). The remaining 7 had slower text entry rates with speech as compared to without, averaging 27.9% (6.3 wpm) slower. For non-text tasks, a large and consistent difference was seen in performance with and without ASR. Subjects averaged 62% slower on these tasks in the Speech-plus condition (p < 0.05).
Speech recognition performance varied widely between subjects, even though all were long-term users and had unimpaired speech. Text entry rate with speech ranged from 3.5 to 31.7 wpm, with an average of 16.7 wpm and a 95% confidence interval of [13.2, 20.2]. Recognition accuracy for text ranged from 72 to 94%, averaging 85% with a 95% confidence interval of [82.3, 88.3]. Subjects spent a substantial amount of time fixing ASR recognition errors. On average, 37% of the total task time in the Speech-plus condition was directly involved in correcting recognition errors.
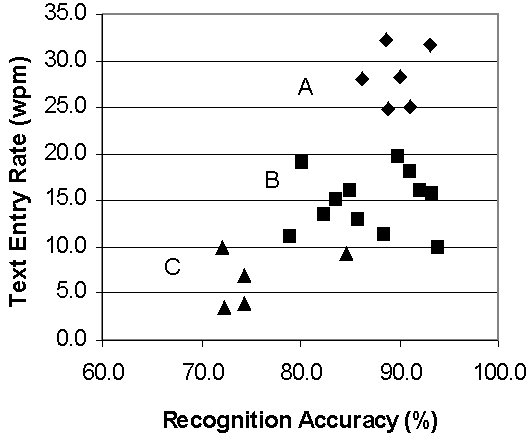 |
Figure 1 shows the relationship between text entry rate and recognition accuracy. There is a tendency for higher accuracy to be associated with higher text entry rate, but the correlation, at 0.62, is not as strong as might be expected. One reason for this is the variation in the average time it took each subject to correct recognition errors, ranging from 11 to 42 seconds per correction, and averaging 23 seconds across subjects. The figure also illustrates the wide range of observed performance. The data points can be grouped into three clusters. Group A, with 6 subjects, had the best overall performance, with text entry rates at 25 wpm or above. Group B, with 13 subjects, achieved text entry rates between 10 and 20 wpm, while the 4 subjects in Group C entered text at 10 wpm or below.
Discussion
The performance of these subjects overall was poorer than might be expected based on previous studies, as only the six Group A subjects entered text as quickly as reported for long-term users without disabilities [1,2]. However, this level of 25 wpm and above may overestimate the "typical" performance that is achieved with experience, as it is based primarily on data from four professional researchers in speech recognition [1,2].
What accounts for the wide range in observed performance with speech recognition? The influence of factors such as school/employment status, amount of ASR training, non-speech typing ability, and ASR usage techniques will be assessed in the next phase of this work. Early impressions are that those who enjoyed the best performance with ASR (Group A) tend to have the highest level of formal education, the fastest manual typing speed, and the fastest hardware. They are not necessarily those with the most formal training in the use of ASR.
The correction strategies employed by users also influences their resulting performance [2]. Fixing ASR errors with the system's correction dialogue allows it to improve its voice model, while use of the general purpose "Scratch That" command actually can degrade the model. Our results support this, as the higher-performing Group A subjects used "Scratch That" only about 10% of the time, while Group C subjects used it almost half the time. Enforcing appropriate correction strategies through clinical interventions is likely to yield enhanced performance with ASR.
References
-
Karat, J., Horn, D.B., Halverson, C.A., and Karat, C. (2000). Overcoming unusability: Developing efficient strategies in speech recognition systems. Poster at CHI 2000, ACM Conference on Human Factors in Computer Systems, The Hague, Netherlands, April 1-4, 2000.
-
Karat, C., Halverson, C.A., Horn, D.B., and Karat, J. (1999). Patterns of entry and correction in large vocabulary continuous speech recognition systems. In Proceedings of the CHI '99 Conference (pp. 568-574). Boston, MA: Association for Computing Machinery.
-
Koester, H.H. (2002). User performance with speech recognition. In Proceedings of the 25th Annual RESNA Conference (pp. 112-114). Washington, DC: RESNA.