DESIGN AND DEVELOPMENT OF SOFTWARE THAT MEASURES SPEECH RECOGNITION PERFORMANCE
ABSTRACT
This paper describes a software-based tool to help clinicians to measure user performance with automatic speech recognition (ASR) systems. A manual tool for performance measurement with ASR systems was developed by Koester [1], which measured speed and accuracy of text entry for users of ASR systems for a subset of tasks which were determined to be of high significance. Automation of this tool takes this tool closer to its initial design goals of ease of use in a clinical context and promises to add data management and outcomes sharing features to the basic functionality of performance measurement.
KEYWORDS
Speech recognition, performance measurement, computer access, outcomes
BACKGROUND
Automatic speech recognition (ASR) is important as a means to access computers [1] for users with disabilities. Measurement of client performance in a clinical and scientific setting is important from the standpoints of evaluating candidate or prescribed ASR tools, evaluating the effect of interventions (e.g. training) over multiple sessions or demonstrating a case for funding prescribed ASR system. Evaluation of human performance in the context of ASR has been carried out in scientific [4] as well as clinical settings [4, 5]. These evaluations characterized speed and accuracy using a variety of measures ranging from errors observed at the word level [5] and at the character level [6]. Input speed has been measured with a variety of yardsticks like turnaround times for ASR generated reports [5], hours of secretary work per line of dictation [4] and words per minute [3]. Thus, a diversity of measurement protocols that have been developed and used for specific tasks, but there is little evidence that suggests wide use of a single protocol.
In the context of clinical use, performance measures need to be user-friendly, reliable and repeatable. With these criteria for suitability for clinical applications, a manual method was developed as a part of a three year study on user performance with speech recognition systems [2]. This was a paper-and-pencil based tool and required the clinician to gain familiarity with the administrative aspects of the test protocol, manually measure the time and score the performance offline after administering the test. Automation using a computer program is expected to eliminate many administrative manual steps, which is the primary goal of the software. Secondary gains from automation of the protocol are: (1) comparing client performance to a database of users with disabilities who use ASR; (2) generating performance history for individual clients; (3) sharing research outcomes from the three year study of use of ASR systems by users with disability [3]; and (4) collecting additional data related to typing performance using non-speech methods to facilitate performance comparisons and validate performance models.
RESEARCH QUESTION
The general goal of this three-year study is to gain insights into the use ASR systems by users with disabilities and gain understanding on whether the ASR systems meet the needs of people with disabilities and to improve user performance with ASR systems. The specific goals of this study are to design and develop computer based software to measure user performance with ASR systems.
METHODS
The software, created using Visual Basic 6, has the following main modules: User Management, Testing, and Reports (see Figure 1).
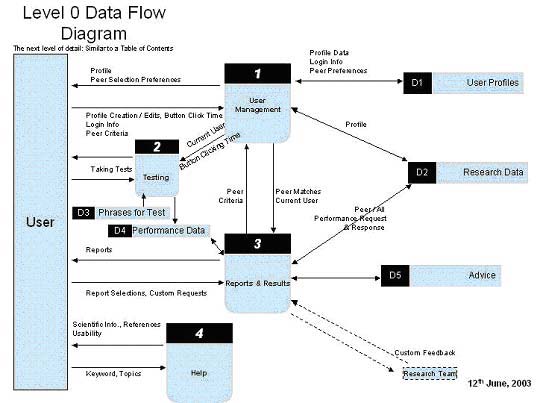 |
User Management.
This module is created for managing data from multiple clients. New accounts can be created and helps generation of login information for clients. Session data is stored in am MS Access TM database on a local storage device.
Testing .
The Testing module is the core module where the algorithms for performance measurement are implemented. A logged in user has the option of taking up to three types of tests: (1) Dictation-Only, (2) Dictation and Correction and (3) Typing Test. The first two are to be taken using ASR and the last test is taken using no-speech input methods. The Dictation-Only test measures the recognition accuracy and the upper limit of the ASR speed achievable, the Dictation and Correction test measures the net accuracy and dictation speed and the Typing Test measures the baseline data for typing speed and accuracy using non-speech input devices. Seven paragraphs are available for test taking. The paragraphs used were developed as a part of the three year study and are matched for length (60-65 words) and reading level (6 th grade)
Accuracy .
The accuracy scoring algorithm, used for evaluating the word level accuracy for the dictation-only and the dictation-and-correction tests is an iterative algorithm. It involves the comparison of the test text (P-text) and the text transcribed by the user during the text (T-text). A correct word implies a correctly spelled and located word. The comparisons are not case sensitive and punctuation marks are counted as words. Accuracy is scored by calculating the percentage words from the P-text which were correctly transcribed in the user's T-text. A general definition used for calculating accuracy is:
The above accuracy calculation in the Dictation-Only test gives the recognition accuracy, in the Dictation-and-Correction test gives the net accuracy. Typing accuracy is identically calculated at the character level. The algorithm tries to overcome the complexity of scoring texts by considering the two text streams, P and T. To consider positional accuracy of words the algorithm follows the following steps: (1) Detect & mark words which are correctly spelled and positioned, (2) contiguous groups of such words divide the T-text into smaller unmarked strings, (3) these unmarked strings are jointly evaluated by going back to step one. Iterations stop when there no additional correct words are detected.
Speed.
Speed is calculated as words per minute (wpm). Number of words is calculated by dividing the number of characters in a text string by 5.5. The time is measured from the point the user clicks the start button on the test screen to activate the input window. Pressing the same button stops the time count.
Reports.
This module will facilitate viewing and printing performance data. This module will contain performance histories and tools for placing a client's performance in the context of other users (either clients or from the research database). An option is available by which one can see the user's transcribed text at various stages of the parsing process, which is helpful in detecting cases where a software error occurs.
DISCUSSION
The software can be used to measure and save ASR related performance data. It allows new user to create an account on the local system. The Testing module displays the performance measures after a user takes a test. The reports module is under development. Future development includes: (1) adding a manual correction option to review & correct the scoring errors as the system may undercount errors for special cases of word combinations in the user generated input text; (2) eliciting feedback from practicing clinicians; and (3) development of the Reports module.
REFERENCES
- Koester, HH. (2001) User Performance with Speech Recognition: A Literature Review. ITalics Assistive Technology, 13,ITalics 116 -130.
- Koester, HH. (2002) A Method for Measuring Client Performance Using Speech Recognition. In Proceedings of the twenty-fifth Annual RESNA Conference. Minneapolis, 115-117.
- Koester, HH. Performance of Experienced Speech Users.In Proceedings of the twenty-sixth Annual RESNA Conference, In Print, 2003.
- Mohr DN, Turner DW, Pond GR, Kamath JS, De Vos CB, Carpenter PC. (2003). Speech recognition as a transcription aid: a randomized comparison with standard transcription. Journal of the American Medical Informatics Association, 10, 85-93.
- Ramaswamy MR, Chaljub G, Esch O, Fanning DD, vanSonnenberg E. (2000). Continuous speech recognition in MR imaging reporting: advantages, disadvantages, and impact. AJR Am J Roentgenol, 174, 617-22.
- Soukoreff, R. W., & MacKenzie, I. S. (2001) Measuring errors in text entry tasks: An application of the Levenshtein string distance statistic. In Extended Abstracts of the ACM Conference on Human Factors in Computing Systems, 319-320, New York, NY: Association for Computing Machinery.
ACKNOWLEDGEMENTS
This development was funded in part by U.S. Dept of Education Grant #H133E980007. Thanks to Dr. Heidi Koester, Dr. Sheryl Ulin, Chris Konrad and S. Rehman for sharing their time, effort, and technical insights.
AUTHOR CONTACT INFORMATION:
RUTHVICK HEMANT DIVECHA, B.E.
30334 Nantucket
Dr.,
Farmington Hills, Mi 48336.
Phone: 248-888-7725
rdivecha@umich.edu