User-Guided Vision-Based Control of a Wheelchair Mounted Assistive Robotic Arm in an Unstructured Environment
M. Hernandez1 , S. Echeverry1 , R. Guerra1 , D.-J. Kim2 , C. Hamilton1, and A. Behal1, 2
1 School of EECS and 2NanoScience Technology Center
University of Central Florida
Orlando, FL 32826
ABSTRACT
A vision based system is proposed to guide the motion of a Wheelchair Mounted Robotic Arm (WMRA) under user supervision. The goal is to facilitate Activities of Daily Living (ADL) tasks in an unstructured environment for wheelchair bound individuals via reduction of cognitive burden. For vision-based manipulation in an unstructured environment, interest object features and homography analysis are used to get necessary information for controlling the robotic arm. Human Computer Interaction is provided using a touch screen-based GUI. For users that cannot take advantage of the touch interface, a joystick, a speech engine, or single switch scanning can be overlaid on the GUI. Experiments suggest that the system can be utilized to robustly perform object grasping tasks.
KEYWORDS
Visual Tracking, Wheelchair Mounted Robotic Arm, Unstructured Environment
INTRODUCTION
Approximately a fifth of the entire population of the United States suffers from some forms of disability. Some of these individuals with diseases and injuries such as Cerebral Palsy, Multiple Sclerosis, Stroke, Spinal Cord Injury, traumatic brain injury, Lou Gehrig’s disease (ALS), and other neuromuscular diseases (NMDs) require extensive rehabilitation in order to maximize their level of independence and increase their participation in society. Over the years, a slew of robotic assist devices have been designed to promote societal reintegration of disabled individuals by means of enhancing function, cutting caregiver cost and reliance, and thereby, promoting a sense of rejuvenated self-esteem.
The Desktop Robot (1) and Powered Aids (2) (i.e., feeding / cleansing assistive devices that have been constructed and programmed for a specific task) have been shown to be well-liked by users. These devices are good at what they do but they are inflexible in the sense that they are able to do a limited amount of tasks in a restricted and static workspace. On the other hand, WMRAs such as the MANUS and the RAPTOR are capable of working in a variable workspace and an unstructured environment. They are capable of picking up miscellaneous objects from floor or shelves as well as carrying objects – tasks that have been identified by users as “high priority” in a collection of pre- and post-development surveys for a multitude of robotic assist devices (3).
The downside to the flexibility and versatility afforded by the WMRAs is that it comes with the need for masterful control of a large number of degrees of freedom. For many users (such as those with traumatic brain injury), the cognitive load is excessive. For other users, the entire process of shifting between layers of menus may be too tedious and frustrating. Recently, a few solutions have appeared in research papers that have targeted vision based control and a variety of interfaces to simplify the operation of the WMRA (4) (5) (6). For a detailed background study, we refer the reader to (9).
In this paper, we discuss the successful design and development of a vision based controller operating underneath a touch screen based GUI to facilitate a subset of Activities of Daily Living (ADL) tasks for wheelchair bound individuals. The paper is organized as follows. Section 2 lays out the research objective. In Section 3, we discuss the approach to solve the problem at hand. Section 4 provides details about the system hardware and the user interface. Results are presented in Section 5. We conclude with a discussion in Section 6.
RESEARCH OBJECTIVE
The research objective is to determine how the user can interactively/efficiently guide the motion of the assistive robotic arm in an unstructured environment. Compared with the commercially available system, we aim for reduction in (a) user’s cognitive burden, (b) time to task completion, and (c) initial training time for familiarization with the device.
METHOD
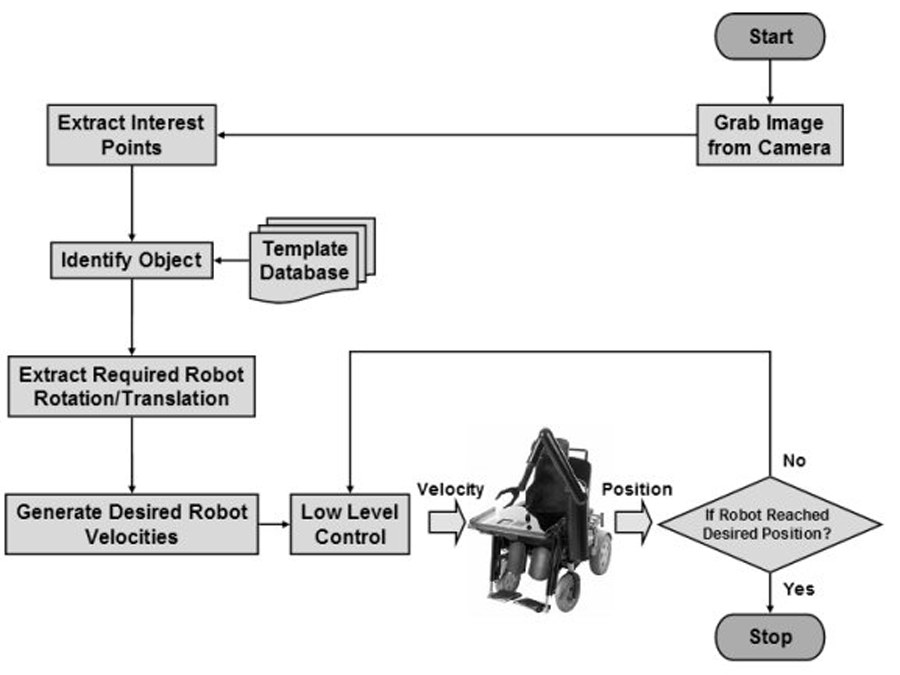 Photo 1: Fine Motion Diagram (Click for larger view)
Photo 1: Fine Motion Diagram (Click for larger view) Our method requires user input at two levels. Initially, the user needs to indicate the approximate location of a desired object1 in the camera’s field of view. Depending on the user’s specific abilities, one may use a joystick or a combination of scanning and progressive quartering. Secondly, the user needs to actively engage (latch) an input device (such as a jelly switch) for the robot to perform its translational and rotation maneuvering toward making a grab – this requirement is primarily to ensure safety.
We break the total motion is broken into two major parts – a gross motion subtask and a fine motion subtask. We remark here that this split into subtasks is automatic and does not require user involvement. The gross motion subtask roughly tries to center the object of interest in the visual field of the camera as well as move in the depth direction, i.e., along the optical axis of the camera. The fine motion subtask both translates and orients the robot’s gripper appropriately to make a grasp. At the end of this step, the user can activate the gripper to make the grasp.
The gross motion subtask has been developed by our collaborators at U. Massachusetts Lowell and various aspects of it have been reported in literature. An abstract from a demonstration at a manipulation workshop can be found in (7). Details of a single switch interface and gross motion have been reported in (8). Most recently, the flexible interface and system flow have been reported in (9).
The handoff from the gross motion subtask to the fine motion subtask is activated when the visual system is able to match a sufficiently large number of features on the desired object with a template in the system’s database. Essentially, the fine motion subtask consists of object identification, motion reconstruction using pseudo-stereo vision, and alignment of the robotic arm (see Fig. 1). We use SIFT (Scale-Invariant Feature Transform) (10) for object identification. Templates for objects of interest are stored as sets of SIFT features. One or more templates for an object may be stored in the database. When an object is seen, new SIFT features are computed and a best match with a template in the database is established. Of course, the use of SIFT stipulates that objects of interest have textured surfaces. Fig. 2 shows an example of the object identification result. The right view shows the most highly matched template image within the prebuilt database. Motion reconstruction is performed by constructing an image homography (11) and then decomposing the Euclidean homography (generated from image homography using camera’s internal model). Finally, robot motion is generated from knowledge of the hand-eye calibration as well as the kinematics of the robot. Along the way, we execute a variety of algorithms (in-house and from standard libraries such as OpenCV and CGAL) to robustify the system against pixel noise, quantization noise, and extraneous features (12) (13). Thus, the robot can steer and drive itself toward making the grasp as long as it is latched by the user. When the robot is seen to be in an appropriate position to make a grab, the user can close the gripper. Then, any sequence of commands can be executed to bring the object to the user or to place it in the lap tray or elsewhere. All of these movements can be commanded within the developed GUI.
 Photo 2: Object Identification (Click for larger view)
Photo 2: Object Identification (Click for larger view) SYSTEM
Hardware
Our assistive robotic arm platform consists of a main computer, robotic arm with its low-level controller, a CCD camera, and user interface. The main computer has an Intel Pentium 4 CPU and two PCI slots which contain a PCI CAN adapter for sending command signals to the robotic arm and PXC200AL Imagenation frame-grabber for receiving captured images from the CCD camera. Based on its popularity, we chose the MANUS Assistive Robotic Manipulator as our robotic arm. Transparent mode enables us to program specific movements of the robotic arm through CAN based communication. To build an Eye-in-Hand configured robotic hand, the PC223XP Color CCD Micro camera is chosen because of its small-size and easy-to-use functionality. Finally, the touch screen-based user interface is built with Advantec FPM-2150G-XCE.
User Interface
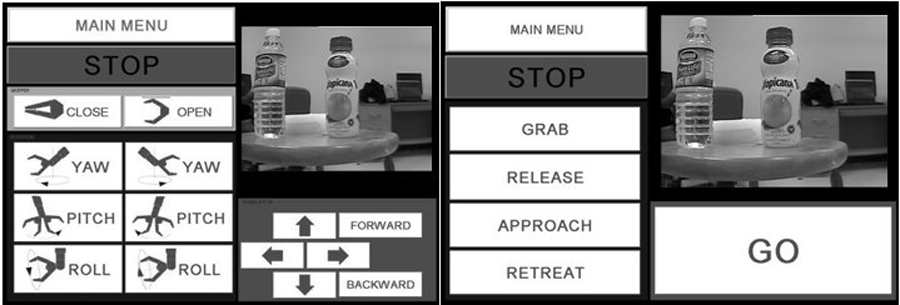 Photo 3: GUI (Click for larger view)
Photo 3: GUI (Click for larger view) In its current state, the user interface is a touch screen-based GUI. This GUI consists of multiple modes to provide various types of control methods. The basic mode is called ‘manual mode’ which is used to control the robotic arm according to the user’s intention. In this mode, the user can control three axis orientation, 3D position, and open/close the gripper of the robotic arm. For safety, the user needs to latch onto the button to generate desired movement. In each motion, a ‘stop’ button is used to terminate all of the motions at any time. Additionally, we developed an ‘auto mode’ for visual tracking operation. Here, when the vision information is available, the user can command the robot to align the robotic hand in front of the target object. A ‘GO’ button is used to replace the 12 rotation and translation buttons in the manual mode. We also provide ‘approach’ and ‘retreat’ buttons to move the robot in either direction along the axis of the gripper. ‘Grab’ and ‘Release’ buttons are also provided. Through the whole process, a live video feedback window (implemented separately but not part of GUI at present time) is utilized to provide the user with the Eye-in-Hand configured camera view. Fig. 3 shows the implemented GUI for manual and auto modes.
RESULTS
 Photo 4: Demonstration (Click for larger view)
Photo 4: Demonstration (Click for larger view) We tested the fine motion system with healthy individuals under three different conditions: (a) 16-button keypad based Cartesian control (commercially available), (b) Touch Screen GUI based Cartesian control, and (c) Touch Screen GUI based Auto Control. The task was to reach and pick a water bottle in front of the user. In case (a), 14 button clicks were needed by the subject to perform the task which took 55 seconds. In this case, the user either needs to memorize the function of each button or refer to a diagram. In case (b), each button on the touch screen based GUI clearly states its function and no memorization is required. In this case, 9 button clicks were needed by the subject to perform the task which took 38 seconds. Finally, the auto mode (case (c)) allowed the subject to perform the task within 33 seconds using only 3 button clicks. In this case, the subject doesn’t need to worry about decomposing required motion into complicated 3D translations and rotation movements. We would like to remark here that the number of clicks and time to task completion is variable under cases (a) and (b) depending on degree of task difficulty and user’s cognitive ability and training. For case (c), a slight variability is expected in time to completion depending on distance to object but the number of clicks is not expected to be variable.
DISCUSSION
Preliminary testing shows that the fine motion system performs the recognition and motion generation tasks robustly. Preliminary results indicate improvement in time to task completion. If the number of clicks can be correlated with cognitive burden, the new system has a remarkable improvement over existing systems. In a mini assistive robotics symposium held at UCF (14), we demonstrated the developed system in the presence of clinicians from Orlando Regional Healthcare (see Fig. 4). Their feedback is being solicited to enhance the usefulness of the system for the target population. It remains to integrate the fine motion system with the gross motion subtask at which time a more complete analysis would be possible. Within the next two months, we expect to be able to overlay the GUI with a speech recognition engine to make the system available to users with upper extremity disabilities.
REFERENCES
- Van der Loos M et al., “Design and Evaluation of a Vocational Desktop Robot”, In Proceedings of RESNA 12th Annual Conference, New Orleans, pp. 534-549, 1989.
- Hoyer H et al., “An Omnidirectional Wheelchair with Enhanced Comfort Features”, In Proceedings of International Conference on Rehabilitation Robotics, Bath, UK, pp. 31-34, 1997.
- Stanger CA et al., “Devices for Assisting Manipulation: A Summary of User Task Priorities”, IEEE Transactions on Rehabilitation Engineering, 2(4): 256-265 (1994).
- Athanasiou P, Chawla N, Leichtnam E, “Assistive robotic manipulator interface,” In Proceedings of IEEE 32nd Annual Northeast Bioengineering Conference, pp. 171-172, Easton, PA, 2006.
- Tijsma H, Liefhebber F, Herder J, “Evaluation of new user interface features for the manus robot arm,” In Proceedings of IEEE International Conference on Rehabilitation Robotics, pp. 258-263, June 2005.
- Dune C, Leroux C, Marchand E, “Intuitive human interactive with an arm robot for severely handicapped people - a one click approach,” In Proceedings of IEEE International Conference on Rehabilitation Robotics, pp. 582-589, The Netherlands, June 2007.
- Tsui KM, Yanco HA, “Human-in-the-Loop Control of an Assistive Robot Arm,” In Proceedings of the Workshop on Manipulation for Human Environments, Robotics: Science and Systems Conference, August 2006.
- Tsui KM, Yanco HA, “Simplifying Wheelchair Mounted Robotic Arm Control with a Visual Interface,” In Proceedings of the AAAI Spring Symposium on Multidisciplinary Collaboration for Socially Assistive Robots, March 2007.
- Tsui KM, Yanco HA, Kontak D, Beliveau L, “Development and Evaluation of a Flexible Interface for a Wheelchair Mounted Robotic Arm,” In Proceedings of the ACM SIGCHI/SIGART Human-Robot Interaction Conference, March 2008.
- Lowe DG, "Distinctive image features from scale-invariant keypoints," International Journal of Computer Vision, 60(2): 91-110 (2004).
- Faugeras O, Three-Dimensional Computer Vision. Cambridge, MA: MIT Press, 2001.
- Fischler MA, Bolles RC, “Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography,” Communication of the ACM 24: 381-395 (1981).
- Boufama B, Mohr R, “A stable and accurate algorithm for computing epipolar geometry,” International Journal of Pattern Recognition and Artificial Intelligence, 12(6): 817-840 (1998).
- Online reference, http://www.eecs.ucf.edu/~abehal/research/robotics/index.html, Homepage of Assistive Robotics Mini Symposium at UCF, Jan. 11, 2008.
ACKNOWLEDGMENTS
This study was funded by the National Science Foundation grant # IIS-534576.
Author Contact Information:
Aman Behal, PhD, School of EECS and NanoScience Technology Center, 12424 Research Parkway Suite 400, University of Central Florida, Orlando, FL 32826, Office Phone (407) 882-2820
EMAIL: abehal@mail.ucf.edu
1 Desired objects are those that have a compact template stored in the software database associated with the system. Our system provides for easy incorporation of novel objects into the database.